
作者: BigLoser 访问次数: 503 创建时间: 2021-02-01 21:50:54 更新时间: 2024-04-20 11:05:07
有个小伙伴面试回来说面试官问了他一些 Redis 问题,但是他好像没有回答上来。
我说,你 Redis 不是用的很溜吗,什么问题难住你了。
他说,事情是这样的,刚开始,问了一些基础的问题,比如 Redis 的几种基本数据类型和使用场景,以及主从复制和集群的一些问题,这些都还好。
然后问 Redis 的两种持久化方式,我说与 RDB 和 AOF 两种方式,RDB 数据文件小,恢复速度快,但是对性能有影响,而且不适合实时存储。而 AOF 是现在最常用的持久化方式,它的一大优点就是实时性,并且对 Redis 半身性能影响最小。
那面试又问了,你知道 AOF 持久化之后的文件是什么格式吗?
答:好像就是文本文件吧?
好,文本文件,那你知道它有什么规则吗?或者说,它和 Redis 的协议有什么关系吗?
答:啊,这个,恩,不太清楚呢。
现在就来看一下 AOF 和 RESP 协议的关系
-
从两种持久化方式说起。
-
RESP 协议是什么
-
动手实现一个简单的协议解析命令行工具
先从持久化说起,虽然一提到 Redis,首先想到的就是缓存,但是 Redis 不仅仅是缓存这么简单,它的定位是内存型数据库,可以存储多种类型的数据结构,还可以当做简单消息队列使用。既然是数据库,持久化功能是必不可少的。
Redis 的两种持久化方式
Redis 提供了两种持久化方式,一种是 RDB 方式,另外一种是 AOF 方式,AOF 是目前比较流行的持久化方案。
RDB 方式
RDB持久化是通过快照的方式,在指定的时间间隔内将内存中的数据集快照写入磁盘。它以一种紧凑压缩的二进制文件的形式出现。可以将快照复制到其他服务器以创建相同数据的服务器副本,或者在重启服务器后恢复数据。RDB是Redis默认的持久化方式,也是早期版本的必须方案。
RDB 由下面几个参数控制。
# 设置 dump 的文件名
dbfilename dump.rdb
# 持久化文件的存储目录
dir ./
# 900秒内,如果至少有1个key发生变化,就会自动触发bgsave命令创建快照
save 900 1
# 300秒内,如果至少有10个key发生变化,就会自动触发bgsave命令创建快照
save 300 10
# 60秒内,如果至少有10000个key发生变化,就会自动触发bgsave命令创建快照
save 60 10000
持久化流程
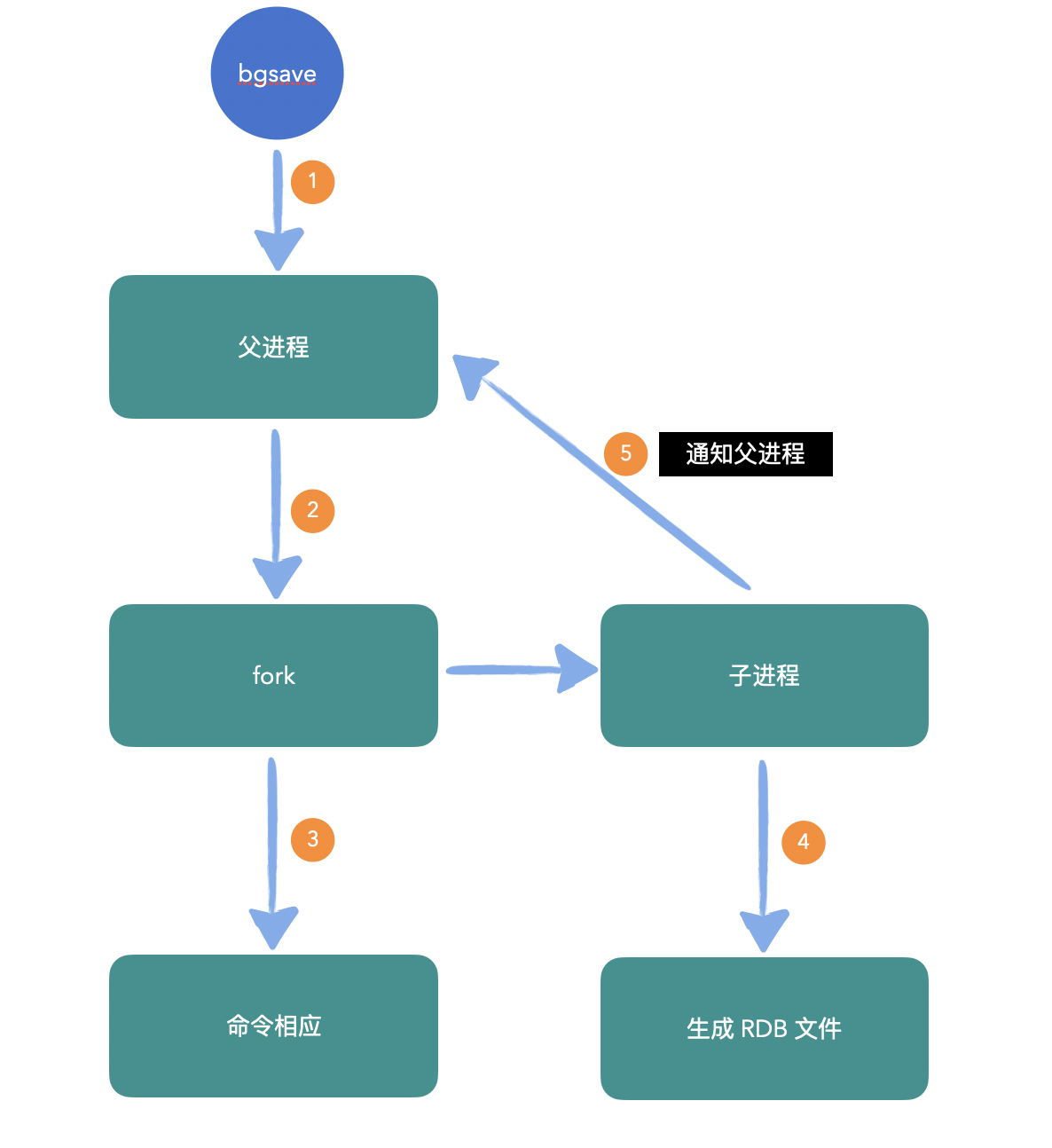
上面说到了配置文件中的几个触发持久化的机制,比如 900 秒、300秒、60秒,当然也可以手动执行命令 save或bgsave进行触发。bgsave是非阻塞版本,通过 fork 出子进程的方式来进行快照生成,而 save会阻塞主进程,不建议使用。
1、首先 bgsave命令触发;
2、父进程 fork 出一个子进程,这一步是比较重量级的操作,也是 RDB 方式性能不及 AOF 的一个重要原因;
3、父进程 fork 出子进程后就可以正常的相应客户端发来的其他命令了;
4、子进程开始进行持久化工作,对现有数据进行完整的快照存储;
5、子进程完成操作后,通知父进程;
RDB的优点:
-
RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据 快照。非常适用于备份,全量复制等场景。比如每6小时执行bgsave备份, 并把RDB文件拷贝到远程机器或者文件系统中(如hdfs),用于灾难恢复。
-
Redis加载RDB恢复数据远远快于AOF的方式。
RDB的缺点:
-
RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运 行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高。
-
RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式 的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题。
AOF 方式
AOF 由下面几个参数控制。
# appendonly参数开启AOF持久化
appendonly yes
# AOF持久化的文件名,默认是appendonly.aof
appendfilename "appendonly.aof"
# AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的
dir ./
# 同步策略
# appendfsync always
appendfsync everysec
# appendfsync no
# aof重写期间是否同步
no-appendfsync-on-rewrite no
# 重写触发配置
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# 加载aof出错如何处理
aof-load-truncated yes
# 文件重写策略
aof-rewrite-incremental-fsync yes
针对RDB不适合实时持久化的问题,Redis提供了AOF 持久化方式来解决,AOF 也是目前最流程的持久化方式。
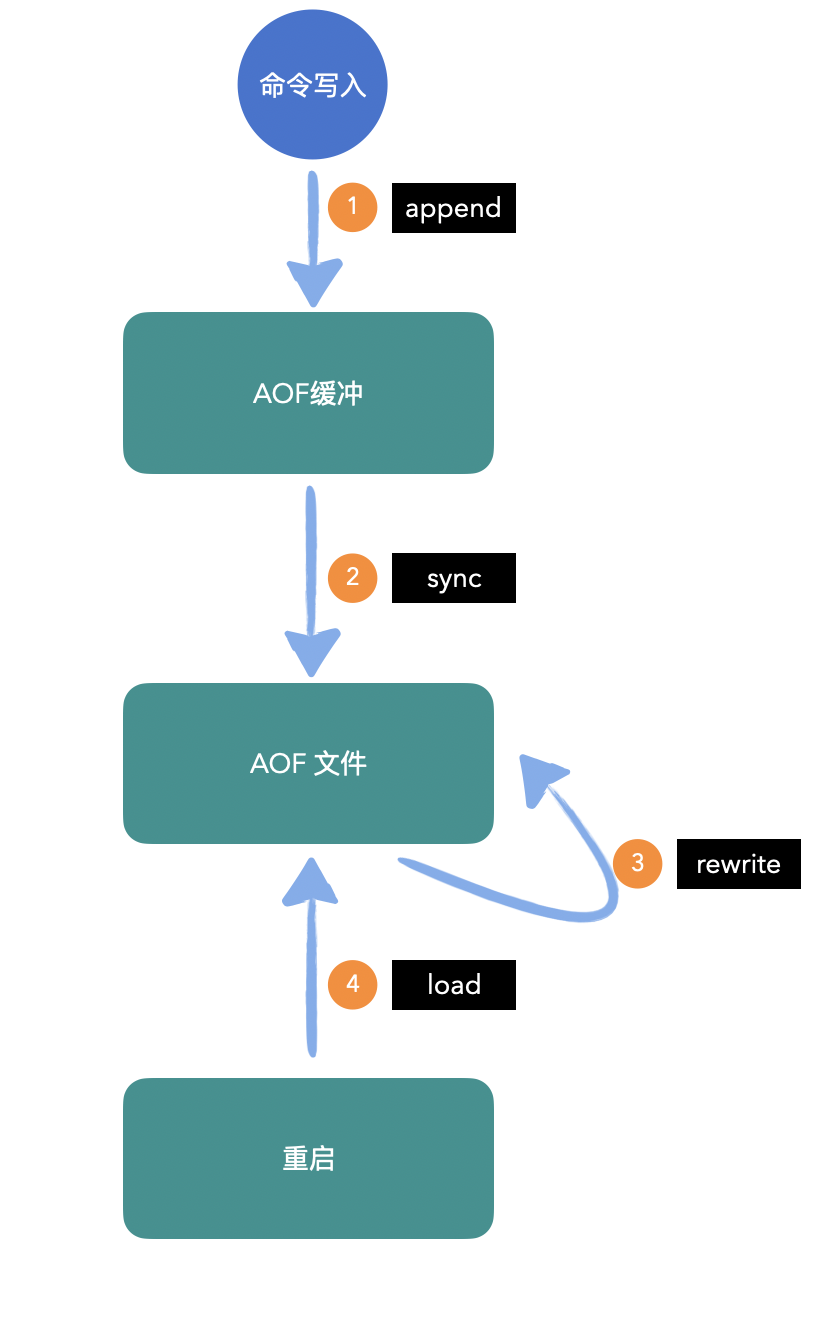
AOF(append only file),以独立日志的方式记录每次写命令, 重启时再重新执行AOF文件中的命令达到恢复数据的目的。
1、所有的写入命令会追加到aof_buf(缓冲区)中;
2、AOF缓冲区根据对应的策略向硬盘做同步操作;
3、随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的;
4、当Redis服务器重启时,可以加载AOF文件进行数据恢复;
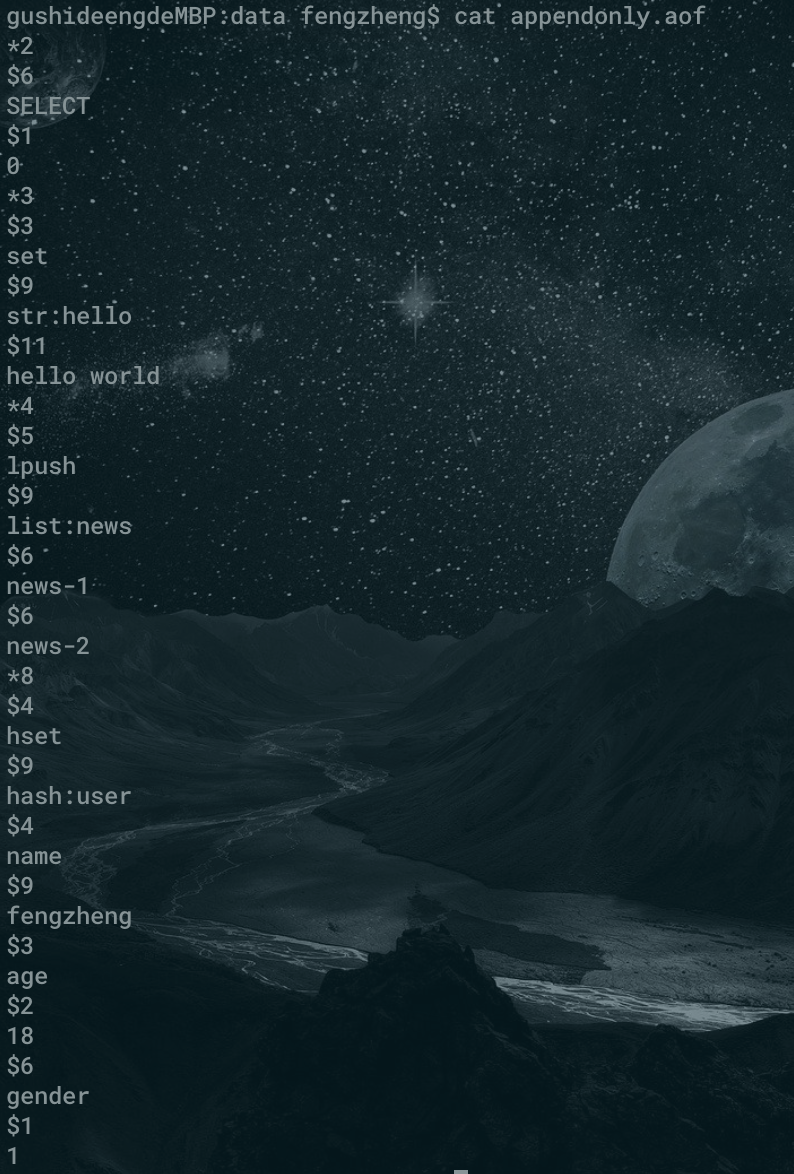
AOF 文件里存的是什么
我在本地的测试 redis 环境中随便刷了几条命令,然后打开 appendonly.aof 文件查看,发现里面的内容像下面这样子。
RESP 协议
Redis客户端与服务端通信,使用 RESP 协议通信,该协议是专门为 Redis 设计的通信协议,但也可以用于其它客户端-服务器通信的场景。
RESP 协议有如下几个特点:
-
实现简单;
-
快速解析;
-
可阅读;
客户端发送命令给服务端,服务端拿到命令后进行解析,然后执行对应的逻辑,之后返回给客户端,当然了,这一发一回复都是用的 RESP 协议特点的格式。
一般情况下我们会使用 redis-cli或者一些客户端工具连接 Redis 服务端。
./redis-cli
然后整个交互过程的命令发送和返回结果像下面这样,绿色部分为发送的命令,红色部分为返回的结果。

这就是我们再熟悉不过的部分了。但是,这并不能看出 RESP 协议的真实面貌。
用 telnet 试试
RESP 是基于 TCP 协议实现的,所以除了用各种客户端工具以及 Redis 提供的 redis-cli工具,还可以用 telnet 查看,用 telnet 就可以看出 RESP 返回的原始数据格式了。
我本地的 Redis 是用的默认 6379 端口,并且没有设置 requirepass ,我们来试一下用 telnet 连接。
telnet 127.0.0.1 6379
然后执行与前面相同的几条命令,发送和返回的结果如下,绿色部分为发送的命令,红色为返回的结果。

怎么样,有些命令的返回还好,但是像get str:hello这条,返回的结果除了 world值本身,上面还多了一行 $5,是不是有点迷糊了。
协议规则
请求命令
一条客户端发往服务器的命令的规则如下:
*<参数数量> CR LF
$<参数 1 的字节数量> CR LF
<参数 1 的数据> CR LF
...
$<参数 N 的字节数量> CR LF
<参数 N 的数据> CR LF
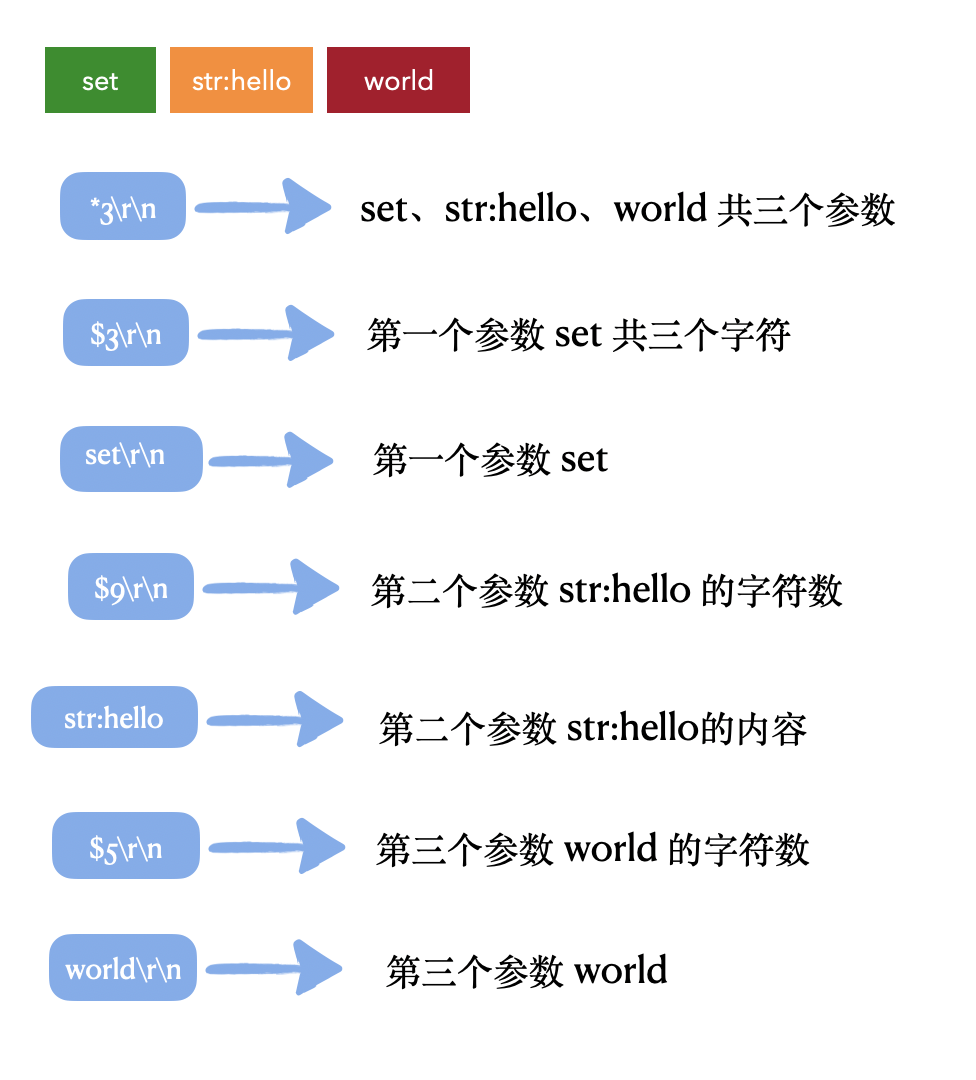
RESP 用\r\n作为分隔符,会表明此条命令的具体参数个数,在命令上看来,空格分隔的都表示一个参数,例如 set str:hello world 这条命令就是3个参数,会表明每个参数的字符数和具体内容。
用这条命令举例,对应到 RESP 协议规则上就会变成下面这个样子:
*3\r\n$3\r\nset\r\n$9str:hello\r\n$5world\r\n
服务端回复
Redis 命令会返回多种不同类型的回复。
通过检查服务器发回数据的第一个字节, 可以确定这个回复是什么类型:
1、状态回复(status reply)的第一个字节是 "+"
比如 ping命令的回复,+PONG\r\n
2、错误回复(error reply)的第一个字节是 "-"
比如输入一个 redis 中不存在的命令,或者给某些命令设置错误的参数,例如输入 auth,auth 命令后面需要有一个密码参数的,如果不输入就会返回错误回复类型。
-ERR wrong number of arguments for 'auth' command\r\n
3、整数回复(integer reply)的第一个字节是 ":"
例如 INCR、DECR 自增自减命令,返回的结果是这样的 :2\r\n
4、批量回复(bulk reply)的第一个字节是 "$"
例如对 string 类型执行 get 操作,$5\r\nworld\r\n,$后面的数字 5 表示返回的结果有 5 个字符,后面是返回结果的实际内容。
5、多条批量回复(multi bulk reply)的第一个字节是 "*"
例如 LRANGE key start stop或者 hgetall等返回多条结果的命令,比如 lrange命令返回的结果:
*2\r\n$6\r\nnews-2\r\n$6\r\nnews-1\r\n
多条批量回复和前面说的客户端发送命令的格式是一致的。
实现一个简单的 Redis 交互工具
了解了 Redis 的协议规则,我们就可以自己写一个简单的客户端了。当然,通过官网我们可以看到已经有各种语言,而且每种语言有不止一个客户端工具了。

比如 Java 语言的客户端就有这么多种,其中 Jedis 应该是用的最多了,既然已经有这么好用的轮子了,当然没必要重复造轮子,主要还是为了加深印象。
RESP 协议基于 TCP 协议,可以使用 socket 方式进行连接。
public Socket createSocket() throws IOException {
Socket socket = null;
try {
socket = new Socket();
socket.setReuseAddress(true);
socket.setKeepAlive(true);
socket.setTcpNoDelay(true);
socket.setSoLinger(true, 0);
socket.connect(new InetSocketAddress(host, port), DEFAULT_TIMEOUT);
socket.setSoTimeout(DEFAULT_TIMEOUT);
outputStream = socket.getOutputStream();
inputStream = socket.getInputStream();
return socket;
} catch (Exception ex) {
if (socket != null) {
socket.close();
}
throw ex;
}
}
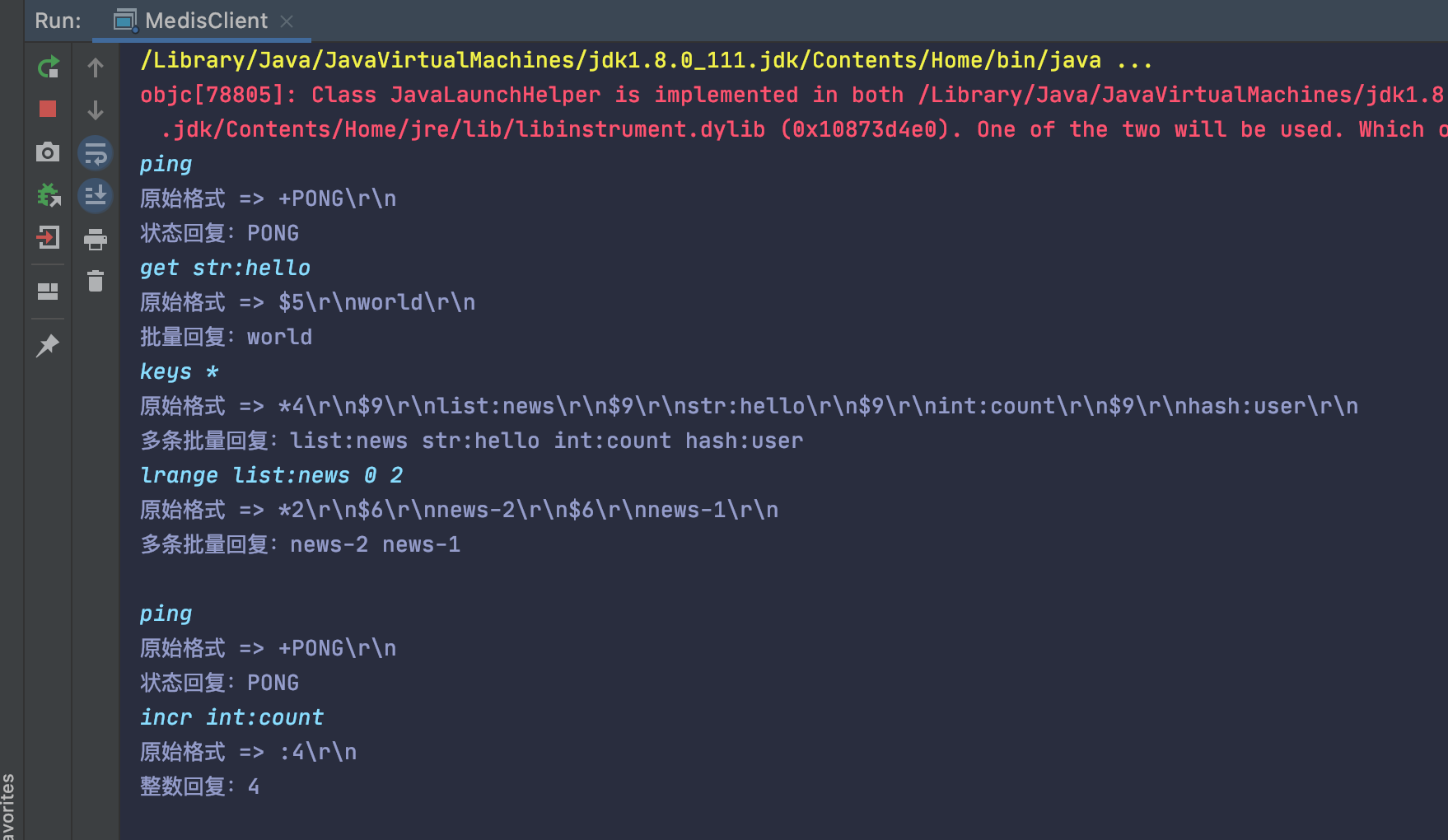
然后剩下的就是对返回的结果进行字符串的解析了,我做的工具就到简陋的到这一步了,下面是一些简单命令的返回输出。






语言: zh-CN
翻译人员:
原作者:
转载地址:
源网址: https://xie.infoq.cn/article/fe2eb9a4cc40eacaa1a4a7511
版权: 本站所有内容, 版权归原作者所有。发表原创内容将会获得现金奖励, 并且随着时间倍数增长, 请了解我们的内容奖励计划。